
AI & Data Engineering
Advance your career into the world of AI and Data Science
Advance your career into the world of AI and Data Science
Started from July 2018, newly updated since 2019, we designed two tracks - data science and business analytics. For the first two months, you will take the fundamental sessions. For the next one month, you will take your own sessions catered to the track you choose. You can also take sessions from both tracks.
The course will be taught by experienced data scientist and machine learning experts from top tech companies. Faculty student ratio reaches 1:5. The course is tailored to meet industrial demands for artificial intelligence and data science positions. Experienced instructors to help you master the most cutting-edge skills in data science.
The companion coursework dives you into the most recent and relevant trends in the data science world: user stickiness analysis, text clustering, spark program development, and deep learning.
Students who took the course have gained offers in technology, finance and consulting industries including data scientist, machine learning engineers, data analytics and business analytics positions.
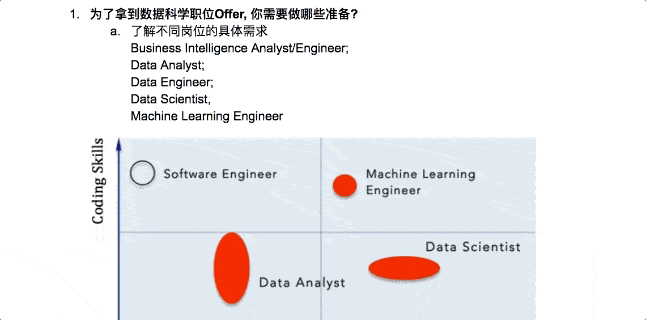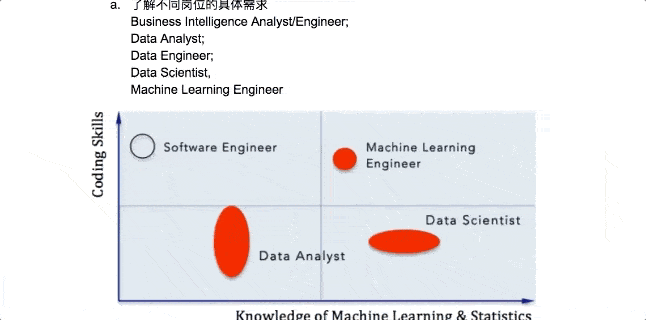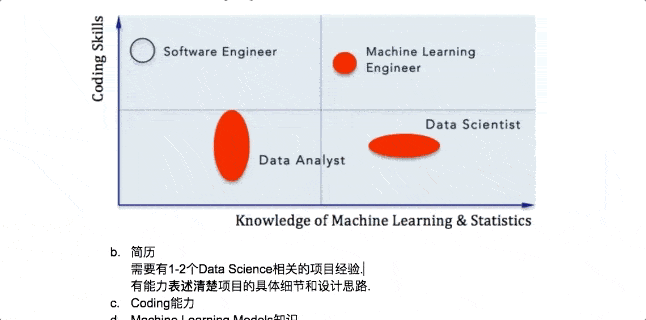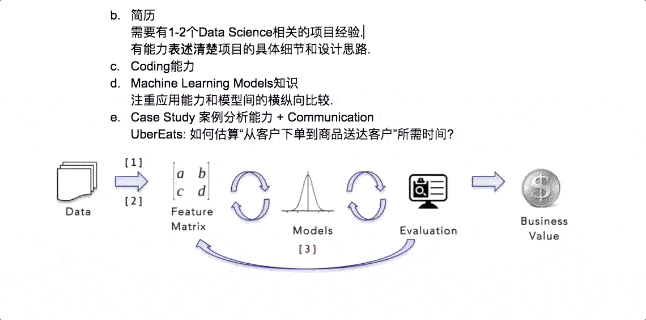
Instructor: Nathan
4 weeks of separate course tracks catered towards your career paths and interview requirements. The tracks are shared and connected with the option to be on both, so you can explore multiple opportunities at the same time.
Focus on developing your business sense with emphasis on business analytics, mathematical statistics, case studies, A/B testing and other necessary skills. Boosts your SQL and Python proficiency to get you ready for business analyst positions.
Gives you an in-depth training of cutting-edge technologies such as distributed systems and deep learning. With a higher standard in coding, we will prepared you for data scientist positions through 4+ machine learning projects.
Customer churn is a common business metric across different industries, like telecommunication, music, and video streaming service, SaaS. Therefore, it is very important to know how to analyze this metric which will influence the company strategy and future.
In this project, we will use different supervised machine learning models to predict if a banking customer will churn or not and do further analysis, then we'll also figure out the key factors related to customer churn, and guide the company to do better business actions to retain valuable customers. By completing the project, you will learn how to use Pandas for data exploration, data analysis, data preprocessing and Sklearn for machine learning models.
With the rise of Internet, customers are increasingly willing to express their opinions. We can find that customers are highly likely to check reviews before purchases and also prefer to share their reviews and user experience, especially for online shopping. So through analysis of customer reviews, the company can better understand customers’ opinions and needs, and can make more informed business decisions. In this project, we’ll use machine learning to analyze an e-commerce company’s customer reviews data and find out the insights and internal relations of the reviews. Further, we can use these information to help us solve some business use cases, like improve conversion rate.
Big data analysis is an essential skill for data scientist. Data scientist needs to build an entire pipeline includes data collection, data cleaning and data modeling.
This project is based on crime data in the San Francisco area. It will lead students to establish a data analysis workflows including data collection, cleaning, storage, and analysis. Based on analyzing and modeling for the crime and weather data, a possible crime event prediction model was established.
Recommendation system is the most profitable department in Google, Facebook, Airbnb, Uber and other startup companies. The ability to design and build a recommendation system is the most important and attractive capability for a data scientist.
This project will lead you to become an expert in building a recommendation system for big data. Netflix movie rating data are used to build the recommendation system, and help you to be and expert in recommendation system by mastering of machine learning algorithm to system implementation. You would come to master the skills on Spark machine learning pipeline building and collaborative filtering model automatically tuning, and apply the built model on Netflix movie rating data.
Kaggle competition is an important test for every Data job seeker. Achieving a good ranking in the competition is one of the best expression of competence and a very crucial criterion for the company to judge talent. In this kaggle competition,we are challenged to analyze a Google Merchandise Store (also known as GStore) customer dataset to predict revenue per customer. You will use LGBM, PyTorch DeepModel to implement your algorithm. This project will also help you get familiar with common strategy for Kaggle and get a good place.
With the rapid development of deep learning technology, more and more Internet companies are beginning to use deep learning in building recommendation systems. Deep learning enables end-to-end learning, compared to traditional recommendation systems.
This project is based on the deep learning model auto-encoder-decoder network, using imdb movie data as training data, and tensorflow to build auto-encoder-decoder model. Features of users and movies are extracted through the model, and the automatic recommendation of movies is finally realized.
Time Series data is very common in our daily life. It is a collection of data obtained by measuring the time series of observations at equal time intervals. For example, the annual sales volume of apparel companies, the price of stocks, the annual precipitation of a city in meteorology, the average monthly temperature, and the PM2.5 index variation etc. Therefore, the analysis of time series data is capable for different real-life applications.
This project is based on the deep learning model LSTM. Students will learn the principle of LSTM models and related technologies for analyzing time series data. This project uses NASDAQ stock data as the training data, and teaches students to build a deep learning model via TensorFlow, which later can be used to predict stock price variation and stock market index.
With the advancement of computer technology, it is now easy to dig out hidden information from unrelated data. For example, in the eighteenth century, stock prices fluctuate with the ships coming and going, because the merchant brought the latest news as well as the cargo. Other studies have found that company executives' visits to the White House can predict the future direction of the company's stock. In this project, we will follow the same line of thinking and analyze the relationship between New York taxis and the stock market. Does the seemingly complicated New York traffic have interesting information hidden?
In this homework, the students will use all the knowledge they have learned to reasonably explore the data, including defining the appropriate business problem, asking reasonable questions, summarizing the data under right metrics, selecting reasonable statistical models, and verifying the conjecture.
In 2017, global retail e-commerce turnover reached 2.290 trillion US dollars, accounting for 10.1% of total retail sales, and is expected to reach 4.479 trillion US dollars by 2021. Year 2018 is the year of online and offline retail revolution - "Future Retail" has taken root and flourished.
In this project, the students will analyze the sales volume and product information of a well-known e-commerce website, systematically learn personalized design, attract new customers and encourage customers to re-shop, optimize commercial marketing channels, and then establish a web product sales forecast model.
"A picture is worth a thousand words". The capability to understand and communicate the data has become an essential skill for analytics professionals. In this project, we will learn foundation and some best practice of data visualization, use Tableau with classic Global Superstore Retail Dataset to perform exploratory analysis and report on sales business case.
Risk control is one of the key metrics in the financial industry. In the era of big data and artificial intelligence, many Internet finance companies and banks are constantly developing and growing big data analytics. Extrapolating patterns and new knowledge from data collected becomes the most important organization capabilities for these stakeholders. This project helps students to learn how to focus on the key metrics in identifying financial risks. By conducting set of exploratory analysis, applying various machine learning techniques, the students will independently develop a solution to predict Lending Club borrower’s default rate.
The class will cover data collection, feature extraction, fraud labeling, credit risk model development and results assessments. These are the key techniques for predicting financial risks in the industry, which makes it especially important for job seekers. After the training has been completed, the students are expected to independently develop a solution to any given financial risk use case.
In various industries, such as Finance, E-commerce, resource sharing, etc, there are all kinds of hidden fraudulent activities. These activities result in direct financial loss. It is a huge challenge for these companies to pinpoint the rare fraudulent activities and minimize financial loss, while maintain good user experience. In this project, we will analysis E-commerce transaction data, study the insight/pattern, and build machine learning solution to give actionable business recommendation for deployment.
20+ instructors to help you master the most cutting-edge skills in data science and achieve your career goals.
Our team consists of senior data scientists, machine learning engineers, and business analysts from Google, Facebook, McKinsey & Company, Linkedin. You will also receive hands-on guidance from Apache Spark/Hadoop contributors and committee members.







You will learn the foundamentals of Data Science including Python basics, linear data structures and search algorithms, and traditional machine learning models.
Frequency: 1 month, 5 sessions/week, 2-3 hrs/session
Introduction of Data Science
Fundamentals of Probability
[Coding] Python Basics 1 variable and syntax
[Coding] Python Basics 2 function and class
Linear Regression & Logistic Regression I
[Coding] Python Basics 3 base data structure
[Coding] Python Binary Search
Logistic Regression II & Regularization
[Coding] Python Array Basic Sorting
Model Evaluation
[Coding] Python LinkedList and Recursion I
[Coding] Python LinkedList & Recrusion I cont
Nonlinear Models I
[Coding] Python Practice
Nonlinear Models II & Feature Selection
[Coding] Python Advanced Sorting and Practice
[Coding] Python Review
PCA & Unsupervised Learning
You will learn Python, data structure and algorithms, improve Coding skills, and enhance your knowledge of mathematical statistics, probability and so on.
Frequency: 3 weeks, 5 sessions/week, 2-3 hrs/session
Data Manipulation in Python 1
[Coding] Python Queue and Stack
[Coding] Python Advanced Sorting and Practice
Data Manipulation in Python 2
[Coding] Python Review
[Coding] Python Review
[Coding] Exam 1
Machine Learning Project 1 - Customer Churn Prediction
[Coding] Python Binary Tree
[Coding] Recursion II - recursion on tree
Machine Learning Project 2 - NLP and Topic Modeling
[Coding] Python Practice
Introduction to statistics
[Coding] Python Binary Search Tree
[Coding] Python review
Resume and Interview Preparation I
Resume and Interview Preparation II
A/B testing 1
[Coding] Python Heap
A/B testing 2
A/B testing 3
[Coding] Python Review
A/B testing 4
Inference in regression
[Coding] String I
SQL I
[Coding] Recursion III DFS
[Coding] Recursion III DFS cont
SQL II
You will study typical Online Assessment, and enter resume review sessions.
Frequency: 2 week, 5 sessions/week, 2-3 hrs/session
[Coding] Exam 2
SQL III
Stats review
[Coding] Probability, Sampling, Randomization
Resume and interview preparation
Career guide: BA vs DS
Online Assessment - deep dive 1
Online Assessment - deep dive 2
Through 4+ Case Studies and Data Challenges, you will enhance your business analytics, case studies, SQL and Python skills and get ready for business analyst positions.
Frequency: 1 month, 4 sessions/week, 2-3 hrs/session
BA track introduction
BA track mock interview
[Coding-for-BA] Queue, Stack
eCommerce deep dive 1: System design
eCommerce deep dive 2: Data driven marketing
eCommerce deep dive 3: Data lab
[Coding-for-BA] HashTable
eCommerce deep dive 4: Data lab
Data visualization In Tableau
Data visualization in Python
[Coding-for-BA] String practice
Case study deep dive 1
Case study deep dive 2
Case study deep dive 3
Anomaly Detection 1
Anomaly Detection 2
Anomaly Detection 3
Supply chain data 1
Supply chain data 2
Review of BA/DA track

Scan the QR code above to
get in touch with Course Specialists